import networkx as nx
import random
def randomize_graph(graph: nx.Graph, preserve_degree=True) -> nx.Graph:
"""
Perform (degree-preserving) randomization on a graph.
:param graph: The input graph to be randomized.
:param preserve_degree: Wether or not to preserve degree.
:return networkx.Graph: The randomized graph.
"""
randomized_graph = graph.copy()
edges = list(randomized_graph.edges)
if preserve_degree:
edge1, edge2 = random.sample(edges, 2)
# Check if they are not connected
if not randomized_graph.has_edge(edge1[0], edge2[1]) and not randomized_graph.has_edge(edge2[0], edge1[1]):
randomized_graph.remove_edge(*edge1)
randomized_graph.remove_edge(*edge2)
randomized_graph.add_edge(edge1[0], edge2[1])
randomized_graph.add_edge(edge2[0], edge1[1])
else:
edge = random.choice(edges)
source = random.choice(edge)
allowed_targets = [n for n in randomized_graph.nodes() if n not in randomized_graph.neighbors(source)] + [source]
if len(allowed_targets):
target = random.choice(allowed_targets)
randomized_graph.remove_edge(*edge)
randomized_graph.add_edge(source, target)
return randomized_graphGraph randomization is not the same as graph randomization
network science
jupyter
In network science, node degree and strength are important properties. When randomising networks one needs to take them into consideration

Recently I haven taken some interest in network science. There are many things to discuss. For this blog post I would like to share my fascination that \(randomization \neq randomization\). In network science, node degree and strength (Fornito et al. 2016) are important properties.
Node degree
In an undirected network the node degree refers to how many edges any given node has. As a linguist, if I wanted to model word relationships using graphs, I need to be aware that word frequency follows a Zipfian distribution. Therefore, the number of connected nodes should follow a similar distribution (if I want to model the same phenomena). Now, provided I wanted to randomise my graph to test wether a specific effect holds, I also need to take care this distribution stays intact. This is why there are two ways to randomize a network:
Degree-preserving randomisation
Taking two links and randomly swapping them (possibly with the condition of not generating multi-links)
Full randomisation
Taking a link, select randomly the source (one of the end), select another random node that is not connected to the source and rewire.
Let’s shuffle some graphs
In order to showcase the effects of different randomization strategies, we first need a function to randomize our graph:
Next we should choose a graph that is particularly sensitive to changes in degree. If we generate a random network with a given degree distribution, such as gnm_random_graph, one would expect suffling of links to have immediate effects on the degree distributions. We can shuffle this graph successivly. You can try this in below’s animation:
from functools import partial
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
plt.rcParams["animation.html"] = "jshtml"
plt.rcParams['figure.dpi'] = 100
plt.ioff()
def animate(frame: int, graph: nx.Graph, preserve_degree=True):
ax.clear()
graph = randomize_graph(graph, preserve_degree)
pos = nx.spring_layout(graph)
nx.draw(graph, pos=pos, ax=ax)
fig, ax = plt.subplots()
n = 200 # 200 nodes
m = 400 # 400 edges
seed = 20160 # seed random number generators for reproducibility
# Use seed for reproducibility
G = nx.gnm_random_graph(n, m, seed=seed)
ani = FuncAnimation(fig, partial(animate, graph=G), frames=20, interval=300)
plt.close()
HTML(ani.to_jshtml())And of course we need a counter-example where we apply full randomization:
fig, ax = plt.subplots()
G2 = nx.gnm_random_graph(n, m, seed=seed)
ani = FuncAnimation(fig, partial(animate, graph=G2, preserve_degree=False), frames=20, interval=300)
plt.close()
HTML(ani.to_jshtml())From visual inspection it is only marginally clear that full randomisation actually distorts our graph over time. We can also try and measure this change quantitatively. To do so, we can compare the degree distribution of both graphs over time steps. They should diverge slowly but steadily. According to (Ray et al. 2012) we can expect them to have fully diverged in the following number of steps:
\(\frac{E}{2} * \ln{\frac{1}{\epsilon}}\)
Generating two identical example graphs yields:
import math
import sys
G3 = nx.gnm_random_graph(n, m, seed=seed)
G4 = nx.gnm_random_graph(n, m, seed=seed)
num_shuffles = (len(G3.edges) / 2) * math.log( 1 / sys.float_info.epsilon)
num_shuffles7208.730677823431We should expect the distributions to have fully diverged by the 7209th iteration. For the sake of simulation, we will consider 10000 time steps.
from scipy import stats
import seaborn as sns
import pandas as pd
results = []
steps = list(range(10000))
degrees = [d for n, d in G3.degree()]
for step in steps:
G3 = randomize_graph(G3)
G4 = randomize_graph(G4, False)
degrees_g3 = [d for n, d in G3.degree()]
degrees_g4 = [d for n, d in G4.degree()]
results.append((step, stats.ks_2samp(degrees, degrees_g3).pvalue, "degree-preserving"))
results.append((step, stats.ks_2samp(degrees, degrees_g4).pvalue, "full"))
df = pd.DataFrame(results, columns=["step", "pvalue", "method"])
fig, ax = plt.subplots()
palette = sns.color_palette()
sns.kdeplot(df, x="step", y="pvalue", hue="method", ax=ax, palette=palette)
ax.plot(steps, [1.0] * len(steps), color=palette[0])
plt.show()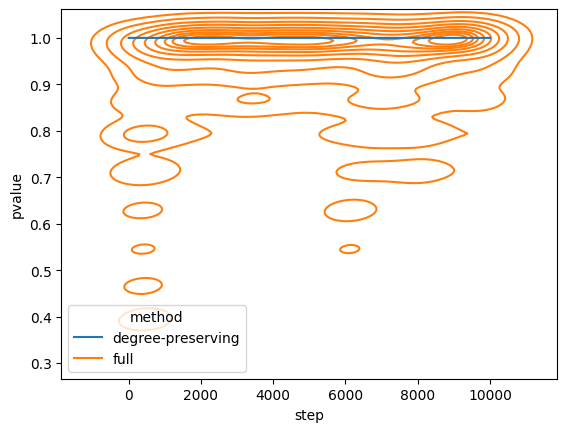
In this experiment we can observe two outcomes:
- degree-preserving randomization does not alter the degree of the network (which is why it is at constant 1.0)
- for full randomization the \(p\) clearly drops at ~500 and ~7000 steps (as predicted)
However, we would only reject the hyphothesis that the degree distribution of G4 and the original graph are independant, if \(p \leq 0.05\). Therefore, we can say that the distribution of degrees is still very similar. This seems to contradict (@ Ray et al. 2012).
References
Fornito, Alex, Andrew Zalesky, and Edward T. Bullmore, eds. 2016. “Chapter 4 - Node Degree and Strength.” In Fundamentals of Brain Network Analysis. Academic Press. https://doi.org/https://doi.org/10.1016/B978-0-12-407908-3.00004-2.
Ray, Jaideep, Ali Pinar, and C. Seshadhri. 2012. “Are We There yet? When to Stop a Markov Chain While Generating Random Graphs.” In Algorithms and Models for the Web Graph, edited by Anthony Bonato and Jeannette Janssen. Springer Berlin Heidelberg.