Using Triton Inference Server’s gRPC interface one could encounter massive performance drops. Taking a look at the benchmark shows the regression has been resolved!
Author
Lennard Berger
Published
November 28, 2023
Space Shuttle Columbia launches from the Kennedy Space Center (NASA)
As with any software architecture, deep learning models need a delivery platform. This is the job of NVIDIA’s Triton Inference Server. The idea is conceptionally simple:
package your model with a definition file, letting Triton know how to process your model
run a simple Docker container from the NGC registry with your models on an S3 or other storage bucket
profit from a standardized inference runtime and built-in metrics
Next to reliability, the main concern of any DevOps engineer will be throughput. What good does it do the production team if models have a 0% downtime, but are so slow as to be unusable?
NVIDIA claims this is where Triton shines, indeed they have a whole section dedicated to model optimization.
I was more interested in a basic feature of Triton, specifically its support for gRPC. In the case of model deployment, gRPC may offer a few distinct advantages:
packing data more tightly (encoding strings or images may waste a lot of bandwith)
repeated handshaking (for HTTP/2 or lower) loses time on every connection. gRPC creates a persistent channel, mitigating this
When choosing your Triton Inference Server version, you need to carefully evaluate the support matrix for your CUDA version. For instance, for CUDA 11.7 (which is still fairly common), you need to use Triton 22.08, which was released on March 27 2021. When I first ran Triton 22.08, to my utter surprise, I found out that gRPC ran several orders of magnitude slower then HTTP requests. There appeared to be a regression with the underlying Python client causing these issues.
With the advent of LLMs the Triton Inference Server has become more and more relevant, which is why I wanted to revisit this issue. In order to do so, I created a small benchmark.
Benchmark
For this benchmark I chose the simplest model I could find from the model repository. Normally I would use locust to run a stress-test to the service. Since Triton’s Python client depends on asyncio rather than gevent, this was not possible. Instead I opted for Molotov.
Using Motolov I evaluated different duration times \(d = {10, 15, 30}\) and number of workers \(w = {1, 5, 10}\).
This benchmark can be run in a few simple steps:
Start the Triton Server via ./run_triton.sh (given you have Docker installed)
Install dependencies from requirements.txt
Run the benchmark script python3 run_molotov.py
Environment
For comparibility, I will include the environment this test was conducted on:
CPU
RAM
Docker Engine
tritonserver
Python
tritonclient
Apple M1 Chip
8GB
20.10.12
23.10-py3
3.10.13
2.36.0
Results
import matplotlib.pyplot as pltimport seaborn as snsimport pandas as pddf = pd.read_csv("results.csv")fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(10, 5))axs[0].set_yscale('log')axs[1].set_yscale('log')sns.lineplot(df, x="duration", y="successes", hue="scenario", ax=axs[0])sns.lineplot(df, x="num_workers", y="successes", hue="scenario", ax=axs[1])plt.show()
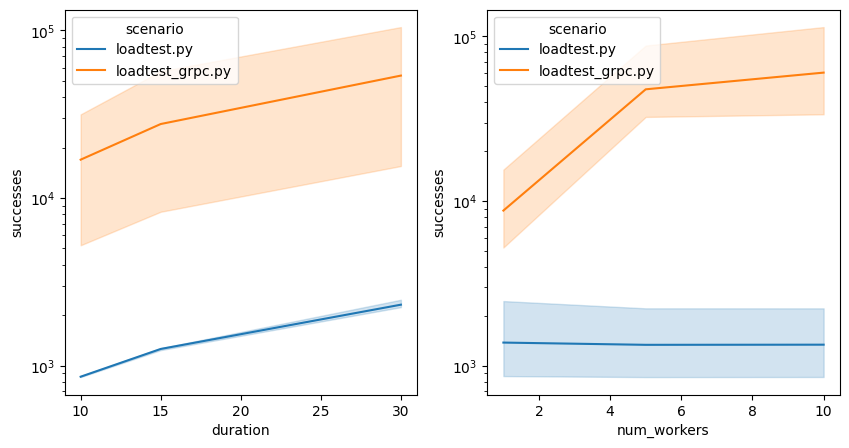
Figure 1: A line plot showing successes in relation to total duration and number of workers
Figure 1 shows the number of successful scenarios executed by type. One can see that longer duration correlates to more successful scenarios. In contrast, we can see the slope of successful scenarios decrease as we increase the number of workers. These are typical trajectories of load benchmarks and indicate that the service is working correctly. From the graph it is immediately obvious that the gRPC scenario has orders of magnitudes more successes then the HTTP scenario.
Discussion
NVIDIA has resolved the regression and (as expected) gRPC now outperforms the HTTP client significantly. This is great news for high-throughput model deployments!
Extending the benchmark
The explicit goal of this benchmark was to test the regression related to gRPC connectivity issues. It would be useful to have a larger suite of benchmarks for the Triton Server however. If you are interested in this, please feel free to use the run_molotov.py as a baseline. Some areas of improvement are:
running more parameters (larger \(d\) and \(w\)) to find out the capacity of Triton